Classification Model to Predict Loan Default

As part of my Insight project, I choose to help Zidisha improve their default detection system. But wait, who is Zidisha?
Zidisha…
Zidisha is a non-profit startup that allows entrepreneurs in developing countries to request credit. Using a crowdsourcing financial model, individuals like Bineta are able to raise the necessary funds to grow their business. This approach allows entrepreneurs to develop sustainable businesses, and provides jobs for additional members in the community.
Bineta's Story

Bineta is a seamstress in Senegal, West Africa whose dresses are in high demand. Right now, she can only produce one or two dresses per week and desperately requires a loan to increase production. With the aim of employing one person from the local area, Bineta has applied to Zidisha for a crowdsourced loan.
My Insight project
Zidisha aims to support entrepreneurs from disadvantaged backgrounds to ensure sustainable development in African communities. This goal, however, is directly undermined by fraud and credit risk as defaulting loans reduce the organisations ability to offer credit for additional loans. To address this issue, I used my time at Insight to:
- Determine factors that influence loan default.
- Develop a system to better predict borrowers defaulting.
Likewise, I split the project into three steps, where I:
- Stored and cleaned data in MySQL.
- Identified variables that influence loan default.
- Developed a risk model using Python and Scikit-Learn.
Developing The Model
I broke the problem into a pipeline with several stages, going from data storage to classification.
Data Storage & Cleaning: Features from over 30,000 records were combined from multiple tables in MySQL, with records cleaned (e.g. imputing and one-hot encoding) and plotted to identify trends. For example, the average defaulting person was shown to have 100 fewer Facebook friends compared to borrowers who paid in full, indicating that a wider social network maximises the likelihood of success!
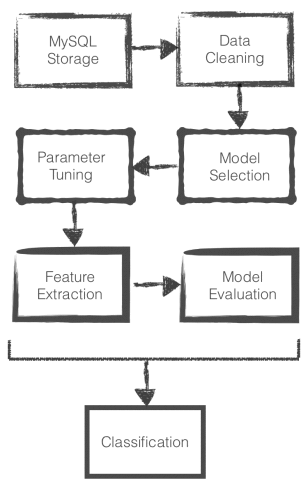
Test and Training Sets: I then split the data into two groups so that 80% was available for model training and 20% for testing.
Model Selection: Selection of an appropriate machine learning algorithm is crucial to ensure meaningful results. The application of logistic regression, for example, required that successful loans be under sampled. The algorithm would simply predict that all loans will eventually pay, if I liked at all data - A 90% rate of accuracy isn’t that bad, after all!
Neural networks and ensemble decision trees were also tested using the scikit-learn machine learning library, but a gradient boosted model was shown to give best results. Such algorithms are amongst the most popular in the industry due to their relatively good accuracy and robustness, but overfitting can be an issue.
Parameter Tuning: The model was initialized from historical data, after which the hyper parameters were optimised using grid search. From there, it was a simple matter of predicting each borrower's likelihood of default on the test dataset.
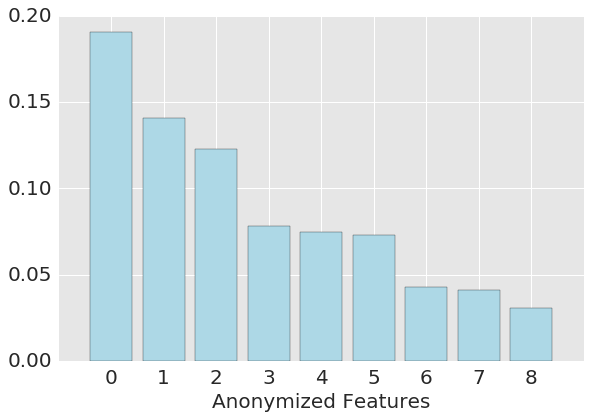
Feature Extraction: During the latter stages of model development, I identified features that best predict loan default. Random forest provides a natural way to assess the importance of independent condtions, and the anonymized results from this process are shown in the following graph. These results are, however, subject to a number of limitations, but I'll leave it up to the reader do some extra reading on that!
Model Validation and Results
Each model is only as good as the accuracy of its predictions. With that in mind, I tested the results on a separate dataset never before seen by the model, quantifying the accuracy with 10-fold cross validation. The R2 score of 74% showed that the Gradient Boosted Model does a great job classifying defaults, and this really give me confidence in the results.
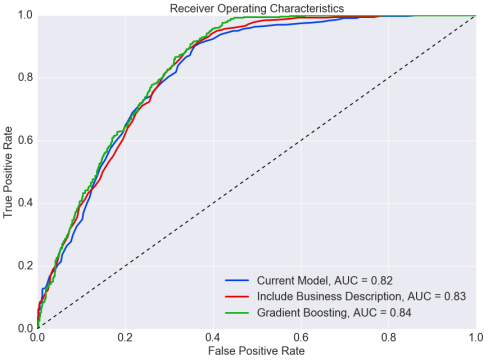
Receiver operator characteristic (ROC) graphs were also used to identify the tradeoff between the number of false positives (i.e. borrowers predicted to default, but don’t) and true positives (i.e. borrowers predicted to default, and do). I was able to increase the area under the curve (AUC) from 82% to 84% with the inclusion of a secret variable, which I won't disclose to ensure Zidisha's privacy. Needless to say, the results were awesome and Zidisha is very happy with the outcome of the project!
Results
In all, I was able to increase the accuracy of Zidisha's model by 8.8% with the inclusion of an additional variable! This secret parameter has huge ramifications for Zidisha itself, as it's equivalent to a $31,000 reduction in annual losses. The result ultimately show that a careful statistical analysis of the data is often required to ensure a detailed underlying knowledge of the data is achieved. Only then are we able to leverage truly leverage the power of machine learning, which is only as good as the data at hand.