Machine Learning Notebook
Machine Learning Notebook
I have a terrible memory. But thing that I find particularly helpful when trying to remember conepts is an ongoing journal of terms. I've traditionally use a moleskin for this task, but have decided to switch to using this blog.
In that spirit, what follows is a live, ever evolving list of ML concepts, links and papers.
Optimisers
Term used to describe algorithms that minimise (or maximise) the objective function. Optimisers tie together the loss function and model parameters by updating the model in response to the output of the loss function. In simpler terms, optimizers shape and mold your model into its most accurate possible form by futzing with the weights. The loss function is the guide to the terrain, telling the optimiser when it’s moving in the right or wrong direction.
-
Types of optimisers:
- Batch Gradient Descent: The grandaddy of all optimisers, computes the gradient of the cost function w.r.t. to the parameters for the entire training dataset. Batch gradient descent is guaranteed to converge to the global minimum for convex error surfaces and to a local minimum for non-convex surfaces. Link here.
- Stochastic Gradient Descent: Instead of calculating the gradients for all of your training examples on every pass of gradient descent, it’s sometimes more efficient to only use a subset of the training examples each time. Stochastic gradient descent is an implementation that either uses batches of examples at a time or random examples on each pass.
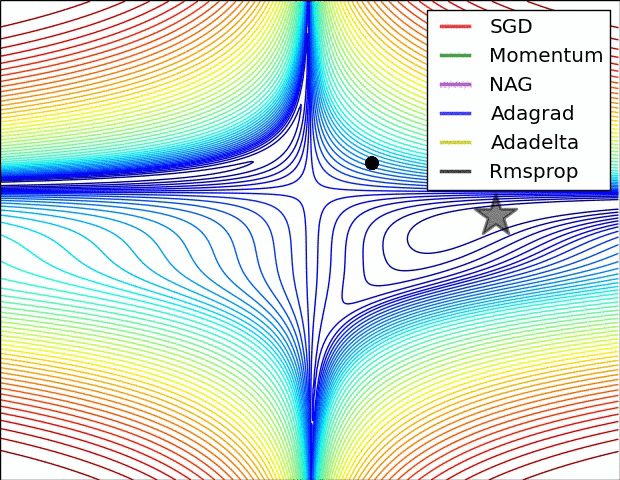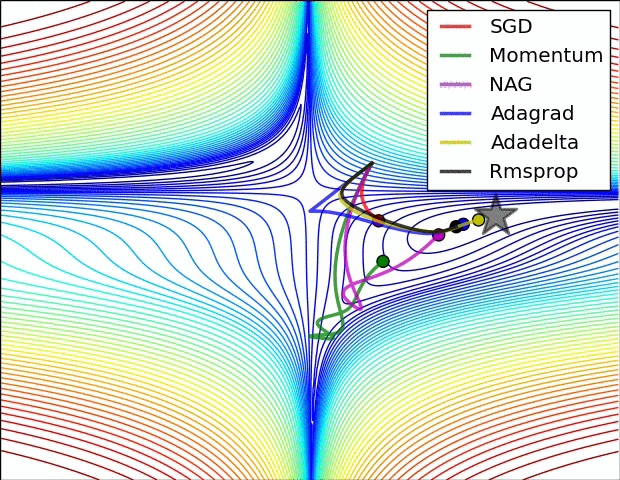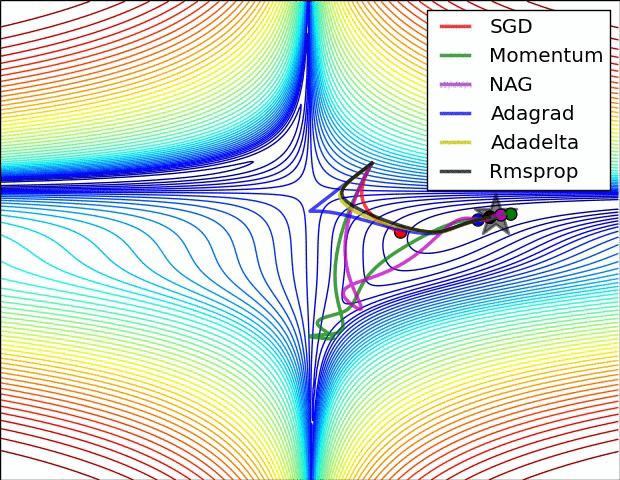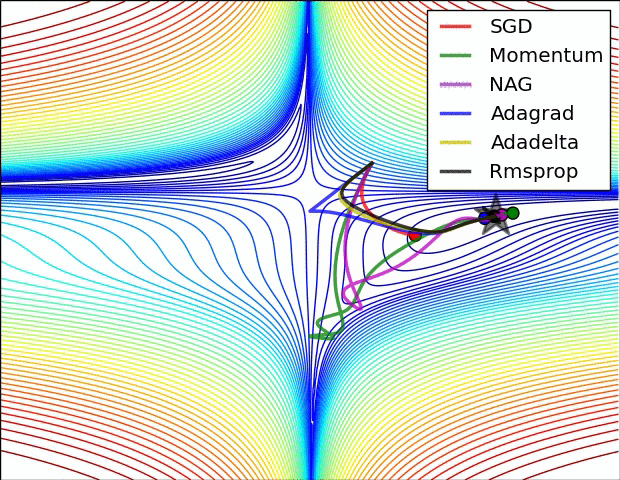
- Adagrad: Adagrad adapts the learning rate specifically to individual features. That means that some of the weights in your dataset will have different learning rates than others. This works really well for sparse datasets where a lot of input examples are missing. Adagrad has a major issue though: the adaptive learning rate tends to get really small over time. Some other optimisers below seek to eliminate this problem.
- One of Adagrad's main benefits is that it eliminates the need to manually tune the learning rate. Most implementations use a default value of 0.01 and leave it at that.
- Adagrad's main weakness is its accumulation of the squared gradients in the denominator: Since every added term is positive, the accumulated sum keeps growing during training. This in turn causes the learning rate to shrink and eventually become infinitesimally small, at which point the algorithm is no longer able to acquire additional knowledge.
- Adadelta: Adadelta aims to resolved the weakness of Adagrad by reducing its aggressive, monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to some fixed size, w.
- RMSProp: RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in Lecture 6e of his Coursera Class. RMSprop was also developed to resolve Adagrad's radically diminishing learning rates. RMSprop is good, fast and very popular optimiser. Andrej Karpathy’s “A Peek at Trends in Machine Learning” shows that it’s one of the most popular optimization algorithms used in deep learning, its popularity is only surpassed by Adam[5].
- ADAM: Adaptive Moment Estimation (Adam) is another method that computes adaptive learning rates for each parameter. In addition to storing an exponentially decaying average of past squared gradients like RMSprop, Adam also keeps an exponentially decaying average of past gradients similar to momentum. Whereas momentum can be seen as a ball running down a slope, Adam behaves like a heavy ball with friction, which thus prefers flat minima in the error surface. More detailed discussion is available here.
Momentum
SGD has trouble navigating ravines, i.e. areas where the surface curves much more steeply in one dimension than in another, which are common around local optima. In these scenarios, SGD oscillates across the slopes of the ravine while only making hesitant progress along the bottom towards the local optimum. Momentum is a method that helps accelerate SGD in the relevant direction and dampens oscillations. It does this by adding a fraction of the update vector of the past time step to the current update vector. Essentially, when using momentum, we push a ball down a hill. The ball accumulates momentum as it rolls downhill, becoming faster and faster on the way (until it reaches its terminal velocity if there is air resistance, i.e. The same thing happens to our parameter updates: The momentum term increases for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions. As a result, we gain faster convergence and reduced oscillation.
Batch Normalisation
To facilitate learning, we typically normalize the initial values of our parameters by initializing them with zero mean and unit variance. As training progresses and we update parameters to different extents, we lose this normalization, which slows down training and amplifies changes as the network becomes deeper. Batch normalization Ref re-establishes these normalizations for every mini-batch and changes are back-propagated through the operation as well. By making normalization part of the model architecture, we are able to use higher learning rates and pay less attention to the initialization parameters. Batch normalization additionally acts as a regularizer, reducing (and sometimes even eliminating) the need for Dropout.
Seq2Seq
Seq2Seq models are particularly good at translation, where the sequence of words from one language is transformed into a sequence of different words in another language. A popular choice for this type of model is Long-Short-Term-Memory (LSTM)-based models. With sequence-dependent data, the LSTM modules can giving meaning to the sequence while remembering (or forgetting) the parts it finds important (or unimportant). Sentences, for example, are sequence-dependent since the order of the words is crucial for understanding the sentence. LSTM are a natural choice for this type of data. Seq2Seq models consist of an Encoder and a Decoder. The Encoder takes the input sequence and maps it into a higher dimensional space (n-dimensional vector). That abstract vector is fed into the Decoder which turns it into an output sequence. The output sequence can be in another language, symbols, a copy of the input, etc.
Imagine the Encoder and Decoder as human translators who can speak only two languages. Their first language is their mother tongue, which differs between both of them (e.g. German and French) and their second language an imaginary one they have in common. To translate German into French, the Encoder converts the German sentence into the other language it knows, namely the imaginary language. Since the Decoder is able to read that imaginary language, it can now translates from that language into French. Together, the model (consisting of Encoder and Decoder) can translate German into French!
- Read this blog for more details.
- For a more scientific approach than the one provided, read about different attention-based approaches for Sequence-to-Sequence models in (this great paper)[https://nlp.stanford.edu/pubs/emnlp15_attn.pdf] called ‘Effective Approaches to Attention-based Neural Machine Translation’.
Attention
The attention-mechanism looks at an input sequence and decides at each step which other parts of the sequence are important. It sounds abstract, but let me clarify with an easy example: When reading this text, you always focus on the word you read but at the same time your mind still holds the important keywords of the text in memory in order to provide context.
An attention-mechanism works similarly for a given sequence. For the example with a human Encoder and Decoder (as described in the Seq2Seq section), imagine that instead of only writing down the translation of the sentence in the imaginary language, the Encoder also writes down keywords that are important to the semantics of the sentence, and gives them to the Decoder in addition to the regular translation. Those new keywords make the translation much easier for the Decoder because it knows what parts of the sentence are important and which key terms give the sentence context. In other words, for each input that the LSTM (Encoder) reads, the attention-mechanism takes into account several other inputs at the same time and decides which ones are important by attributing different weights to those inputs.
- The original Attention is all you need paper.
- To learn more about attention, read this article.
Transformer
The paper ‘Attention Is All You Need’ introduces a novel architecture called Transformer. As the title indicates, it uses the attention-mechanism we saw earlier. Like LSTM, Transformer is an architecture for transforming one sequence into another one with the help of two parts (Encoder and Decoder), but it differs from the previously described/existing sequence-to-sequence models because it does not imply any Recurrent Networks (GRU, LSTM, etc.).
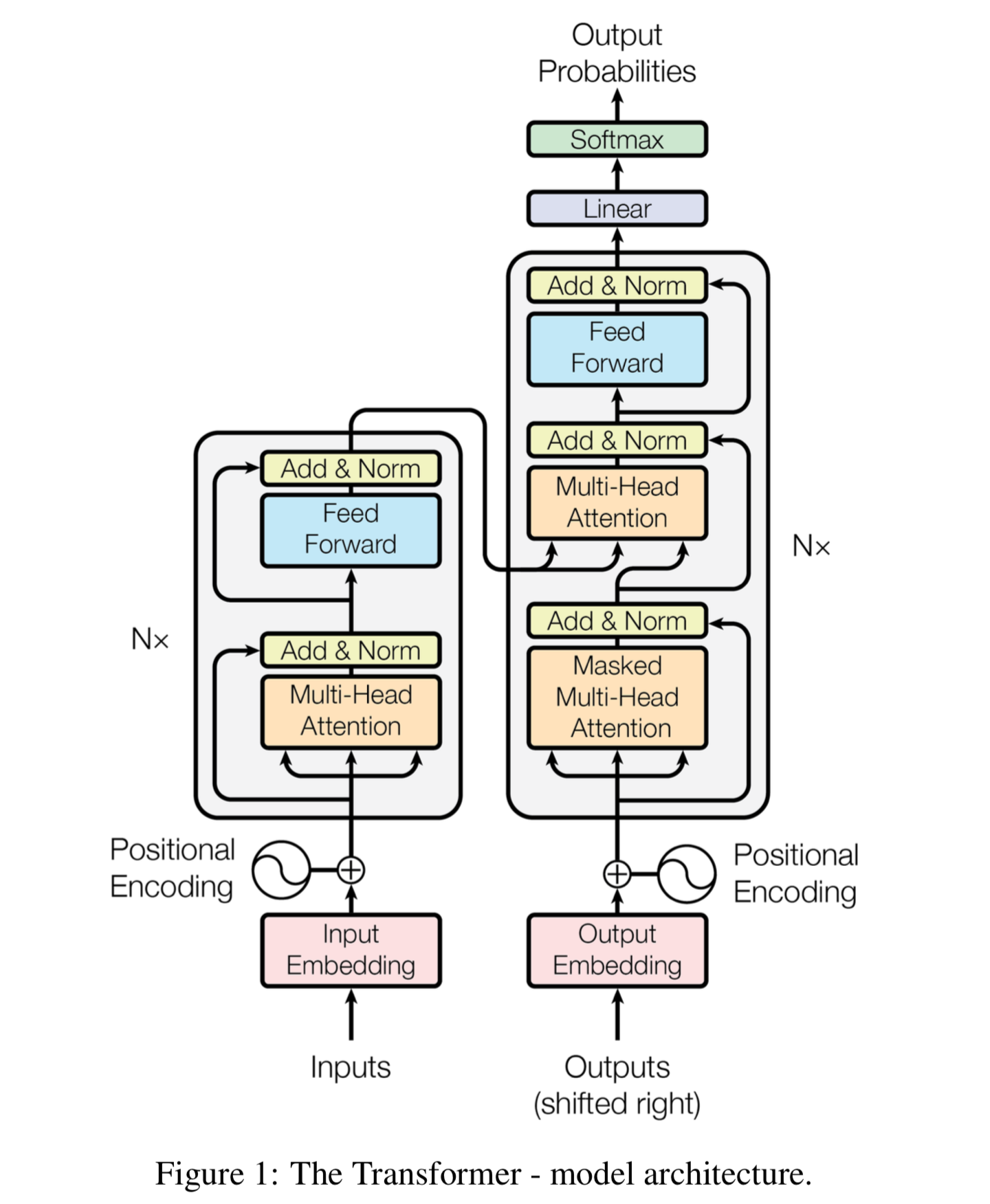
The Transformer consists of two main components: a set of encoders chained together and a set of decoders chained together. The are used in the following way:
- The function of each encoder is to process its input vectors to generate what are known as encodings, which contain information about the parts of the inputs which are relevant to each other. It passes its set of generated encodings to the next encoder as inputs.
- Each decoder does the opposite, taking all the encodings and processing them, using their incorporated contextual information to generate an output sequence.
- To achieve this, each encoder and decoder makes use of an attention mechanism, which for each input, weighs the relevance of every input and draws information from them accordingly when producing the output. Each decoder also has an additional attention mechanism which draws information from the outputs of previous decoders, before the decoder draws information from the encodings. Both the encoders and decoders have a final feed-forward neural network for additional processing of the outputs, and also contain residual connections and layer normalisation steps.
Links:
- See this illustrative description of the transformer for more details.
- Here is an excellent article giving an overview of what a transformer is.